


Subsquid (SQD): A Blue-Chip Hiding in Plain Sight
neglected & misunderstood, SQD should re-rate 20x near-term and has 250x potential longer-term

(M31 Capital recently initiated a position in SQD)

Subsquid Network is the industry’s first modular indexing and querying solution for blockchain data, enabling developers to efficiently access and analyze on-chain information. It provides a uniquely modular and scalable architecture, allowing for highly customized data pipelines and real-time updates. The project is not well known or understood by the market, creating a rare and highly attractive investment opportunity.
Blockchain Data Management is Broken
One of the biggest challenges Web3 developers face today is accessing data at scale. It's currently highly complex to query and aggregate the exponentially growing amount of data produced by blockchains (transactions and state data), applications (decoded smart contract states), and any relevant off-chain data (prices, data kept in IPFS and Arweave, pruned EIP4844 data). This data is often fragmented across multiple ecosystems, chains, and technologies, leading to non-standardized structures and silos. This fragmentation results in incomplete datasets, making it difficult to extract meaningful insights.
In Web2, data is stored in centralized data lakes like BigQuery, Snowflake, Apache, and Iceberg to facilitate access. However, storing Web3 data in similar centralized data lakes would defeat the purpose of open, resilient access. If aggregated, filtered, and easily extractable, Web3 app data can unlock the potential of the industry in a multi-chain paradigm with next-generation application functionality.
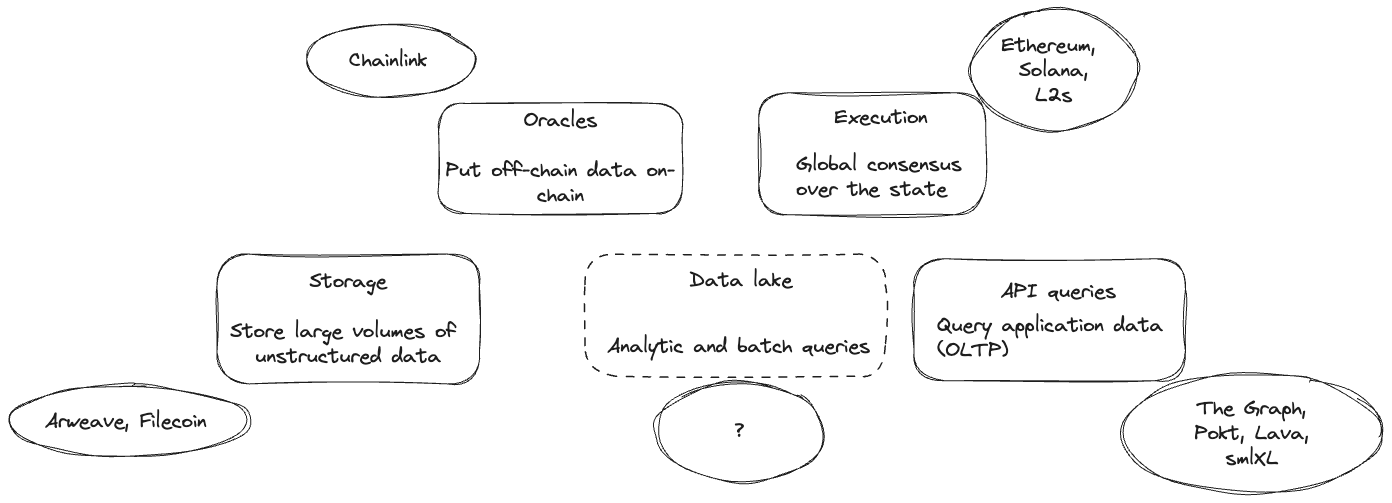
Solution: Subsquid Network
Subsquid is a decentralized query engine optimized for efficiently extracting large volumes of data. It currently processes historical on-chain data from over 100 EVM and Substrate networks, as well as Solana (in beta) and Starknet. The data includes comprehensive details such as event logs, transaction receipts, traces, and per-transaction state diffs for EVM. It is also developing coprocessor & RAG functionality, leveraging its multi-chain indexing capabilities with ZK prover marketplaces and TEEs, to trustlessly connect smart contracts with its network of off-chain data lake resources.
Traditional methods of querying blockchain data are slow, fragmented, and costly, making it difficult for developers to extract meaningful insights. Subsquid's decentralized query engine offers a scalable, modular architecture that allows for customized data pipelines and real-time updates, making data extraction up to 100x faster and reducing costs by up to 90% compared to centralized solutions.
Current Product Suite
These tools enable developers to efficiently access and analyze large volumes of blockchain data, making it easier to build and scale more complex decentralized applications.
Subsquid Network: A distributed query engine that processes historical on-chain data from over 100 EVM and Substrate networks, as well as Solana (in beta) and Starknet.
Squid SDK: A TypeScript toolkit for building indexers on top of the Subsquid Network, offering high-level libraries for data extraction, transformation, and loading.
Subsquid Cloud: A Platform-as-a-Service for deploying Squid SDK indexers, featuring provisioning of Postgres resources, zero downtime migrations, and high-performance RPC endpoints.
Subsquid Firehose: An open-source lightweight adapter that facilitates the development and deployment of subgraphs without the need for extensive setup.
Modular Architecture
What sets Subsquid apart from other solutions in the market is its uniquely modular architecture, which allows optimal flexibility and customization for developers. This will be a key differentiator as we enter the next phase of Web3 development, to more complex and feature-rich applications and use cases.
Customization: Developers can tailor each component of the data processing pipeline to meet specific needs, allowing for more efficient and effective data handling.
Scalability: The modular nature facilitates horizontal scaling, making it easier to handle increasing data loads by simply adding more processing nodes.
Flexibility: The ability to independently develop and optimize different stages of the pipeline means that Subsquid can adapt to various use cases and performance requirements.
Efficiency: By allowing fine-grained control over the data flow and processing logic, Subsquid can achieve higher performance and efficiency in indexing and querying tasks.
To illustrate the power of the modular approach for data access, we can compare analytics and real-time data access use-cases. Both require an efficient source of on-chain data (Subsquid Network), but the rest of the pipeline requires completely different technologies. In the Web2 world, real-time data access for applications is typically powered by relatively small transactional databases (Postgres, SQLite), while analytics requires big data solutions like Snowflake, BigQuery or Trino. The same differentiation applies to Web3 uses cases and Subsquid is uniquely positioned to capture a meaningful value share from both verticals.
Target Markets & Use Cases
Subsquid's technology is highly relevant across all sectors of the blockchain ecosystem:
dApp Projects: Enhancing performance and user experience for decentralized applications in DeFi, NFTs, gaming, social media, and more.
Blockchain Networks: Improving data infrastructure for L1 and L2 networks, enabling developers to build higher-utility, data-driven applications.
Analytics and Research: Assisting firms in processing large volumes of blockchain data for insights and trends.
The value-per-byte of on-chain and Web3 data is orders of magnitude higher than in Web2, and is consumed by smart contracts, indexers, analytics APIs, and edge technologies like AI agents.

Customer Case Studies
Railgun: Privacy-focused EVM wallet infrastructure
Railgun had previously scanned balances using an in-house tool that called the RPC directly. This was quite slow, so they experimented with using an indexer, initially The Graph. However, they desired to go multi-chain and found that The Graph didn’t have feature parity on all chains they were interested in supporting.
Their new product, ‘privacy pools,’ required an additional upgrade in balance scanning speeds, and the team found this to be only possible with Subsquid.
CoinList: Leading token launch platform
Since CoinList frequently deals with new projects, getting a node provider for chains they intend to support is often a hassle. New and small chains are not supported by major providers, and depending on small providers can be difficult and unreliable. It is also not advisable to get data from a project team itself, as this infrastructure can be tampered with or simply not well maintained. Subsquid enables CoinList to bypass this issue entirely.
The platform is highly interested in Subsquid’s upcoming native support for hot blocks in the data lake, as this will remove the RPC constraint entirely. This open opportunity for defragmentation not just for token launch platforms like CoinList, but for all kinds of dApps and multichain platforms, like games and social, that may require information from across ecosystems of all sizes.
Neglected & Misunderstood
One of the primary reasons Subsquid is so undervalued today is its lack of visibility in the market. Despite its differentiated technology, valuable functionality, impressive early traction, and exciting upside potential, the project has not received the attention it deserves. This oversight can be attributed to several factors:
Weak Brand Marketing: Subsquid has admittedly spent its first few years focused solely on product development and customer acquisition, under-indexing on brand marketing. Its social media presence and marketing campaigns to-date have not effectively communicated its value proposition to a broader audience.
Lackluster Token Launch: Given its underwhelming marketing efforts, the launch of the SQD token did not generate the hype typically seen with other blockchain projects, leading to a lower initial valuation.
Esoteric Technical Differentiation: The advanced and technical nature of Subsquid's offerings may have been difficult for the broader market to understand and appreciate.
With the team now focused on brand awareness, and with the help of strategic partners like M31 Capital, we believe the project will be able to better communicate its value to the market, which should drive a significant near-term valuation re-rate.
Competitive Landscape
Subsquid’s primary competition for blockchain data indexing are The Graph, Zettablock, and Space and Time. Each platform has its unique strengths and weaknesses, making the choice dependent on specific project requirements. Ultimately, we believe the Web3 data lake/warehouse market will be enormous long-term with multiple large winners.
The Graph
Predefined Subgraphs: The Graph relies on subgraphs, which are predefined sets of instructions for indexing and querying data. While this approach provides a structured and user-friendly method, it lacks the deep customization offered by Subsquid’s modular processors.
Indexing Mechanism: The Graph uses a more rigid indexing mechanism where changes to the indexing logic often require significant adjustments or redeployments of subgraphs.
Performance: Offers moderate to high performance depending on the complexity of the subgraph and network load. It provides low latency for queries and can scale horizontally by adding more indexers.
ZettaBlock
Centralized Control with Decentralized Intent: ZettaBlock combines centralized infrastructure with decentralized trust mechanisms. This approach provides real-time data indexing and querying capabilities but does not offer the same level of modular customization found in Subsquid.
Data Pipelines: ZettaBlock focuses on real-time data pipelines with customizable ETL (Extract, Transform, Load) processes but within a more centralized control framework compared to Subsquid’s fully decentralized and modular approach.
Performance: Designed for real-time data indexing with low query response times. It is highly scalable and suitable for applications needing real-time data pipelines.
Space and Time
Proof of SQL and Hybrid Processing: Space and Time emphasizes data integrity with Proof of SQL and supports hybrid transactional and analytical processing. While it offers advanced features for data integrity and processing, its architecture is not as modular or customizable in terms of the indexing pipeline as Subsquid.
Data Warehouse: Space and Time’s architecture centers around a decentralized data warehouse, which, while powerful for large-scale data queries, is more monolithic compared to Subsquid’s flexible, modular pipeline.
Performance: Provides high performance with optimizations for both blockchain and off-chain data. Supports hybrid transactional and analytical processing, ensuring low latency and scalability.
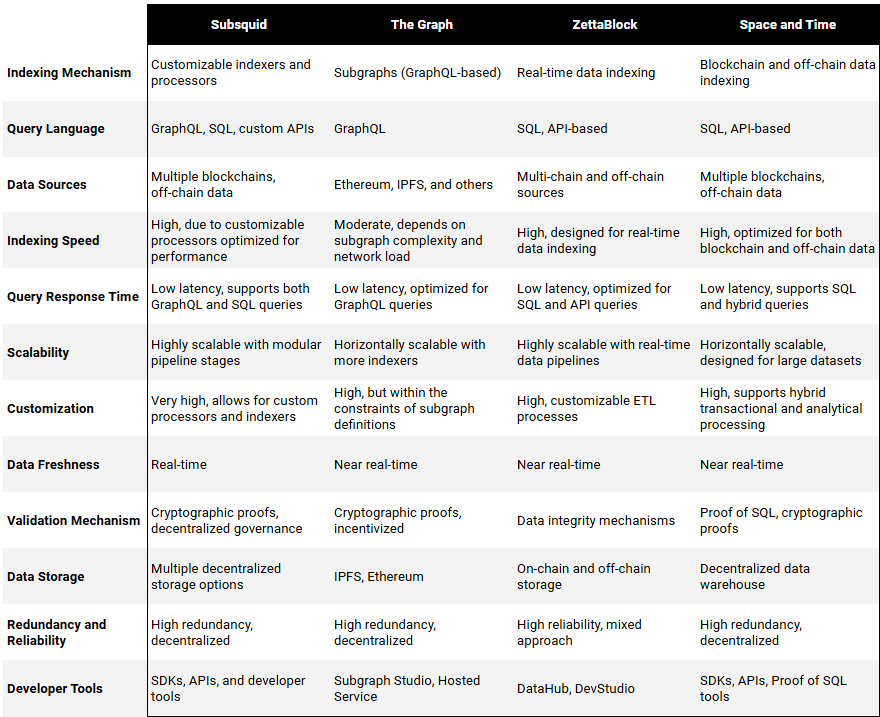
Subsquid Differentiation
Subsquid's unique approach to modular and customizable data processing, combined with its focus on flexibility, performance, and scalability, sets it apart from other blockchain data indexing and querying platforms. We believe this functionality will become increasingly valuable as the industry matures and applications become increasingly more multi-chain and complex.
Customizable Indexers and Processors
Flexible Indexing: Subsquid allows developers to build highly customizable indexers and processors, which can be tailored to specific use cases. This flexibility makes it easier to handle complex data integration tasks and extract meaningful insights from blockchain data.
Performance Optimization: Custom processors can be optimized for performance, ensuring that indexing and querying are efficient and scalable.
Multi-Stage Processing Pipeline
Data Flow Architecture: Subsquid employs a multi-stage processing pipeline that separates data extraction, transformation, and storage into distinct stages. This architecture improves the manageability and scalability of data processing tasks.
Modularity: Each stage of the pipeline can be independently developed and optimized, providing greater control over the data processing workflow.
Support for Multiple Data Sources
Diverse Blockchain Integration: Subsquid supports multiple blockchains and can integrate with various databases, making it a versatile tool for developers working across different blockchain ecosystems.
Adaptability: The platform's ability to handle multiple data sources ensures it can adapt to the evolving needs of the blockchain industry.
Developer-Friendly Tools and SDKs
Comprehensive SDK: Subsquid offers a Software Development Kit (SDK) that includes tools and libraries to simplify the development of custom data indexers and processors.
API Support: The platform supports various APIs for querying data, including GraphQL and SQL, providing flexibility for developers in how they access and use the data.
Decentralized and Scalable Architecture
Decentralized Processing: Like The Graph and Space and Time, Subsquid leverages a decentralized network of nodes to process and index data, ensuring high availability and fault tolerance.
Scalability: The platform is designed to scale horizontally, allowing it to handle increasing amounts of data and growing numbers of queries efficiently.
Performance and Efficiency
High Performance: By allowing custom optimizations at various stages of the data processing pipeline, Subsquid can achieve high performance in data indexing and querying tasks.
Efficient Resource Use: The platform's architecture ensures efficient use of computational resources, reducing the cost and complexity of data processing.
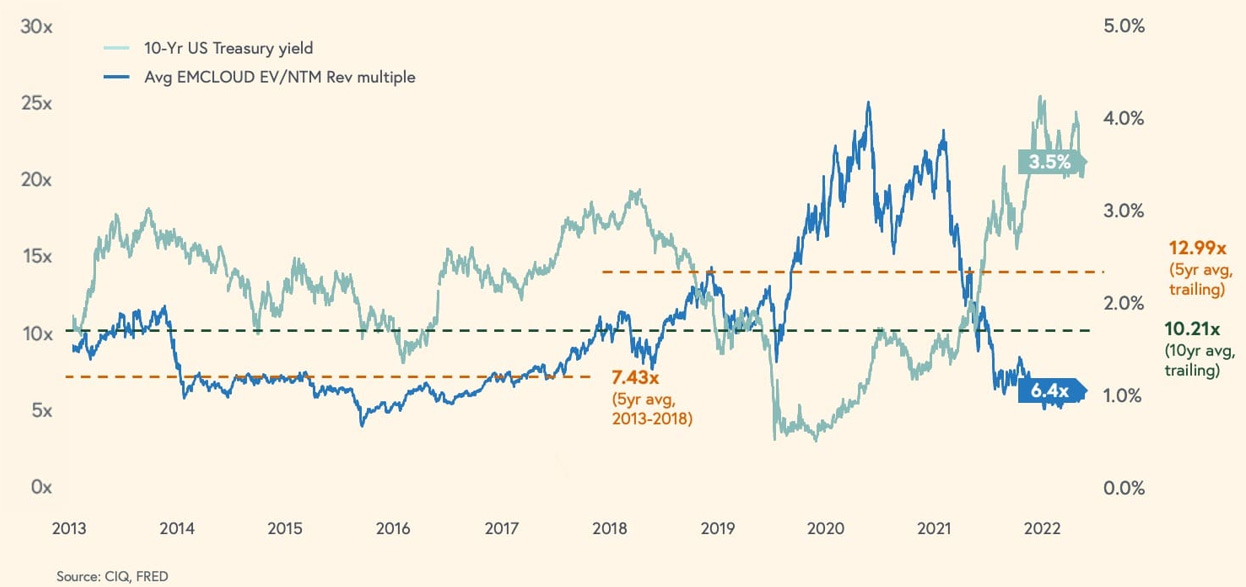
The last point is especially important when comparing Subsquid to The Graph, the most mature competitor in space, which has highly inefficient network operations and unsustainable economics. As illustrated below, token incentives grossly exceed network revenue by 50x-100x each month:

Architecturally, The Graph's “monolithic” indexing node is a black box that executes subgraphs compiled into WASM. The data is sourced directly from the archival node and local IPFS, and the processed data is stored in a built-in Postgres database. In contrast, Subsquid Network offers near zero-cost data access, more granular data retrieval from multiple blocks, and superior batching and filtering capabilities.

Relative Valuation
Subsquid’s best liquid token comp is GRT, which trades at 18x FDV premium to SQD. Space and Time will be another direct comp when the token starts trading later this year, which should also be a catalyst for SQD, drawing market attention to the value of the Web3 big data sector.
Longer-term, as the Web3 industry matures, it’ll be reasonable to compare Subsquid to similar Web2 companies today, implying up to 270x upside if the project (and Web3 at large) is successful.

2030 TAM & Upside Potential
Although blockchain data management, and Web3 in general, is still in its infancy, we can look to Web2 as a reference for Subsquid’s longer-term TAM. I’ve previously sized the potential upside for the entire 2030 Web3 market, which results in $5.6t in Web3 GDP (total revenue) by 2030. If we take the ratio of the Web2 Data Lake and Warehouse markets as a percentage of total Web2 GDP, we can apply it to the Web3 GDP forecast, resulting in a Web3 Data Lake and Warehouse market of $23.6b by 2030.
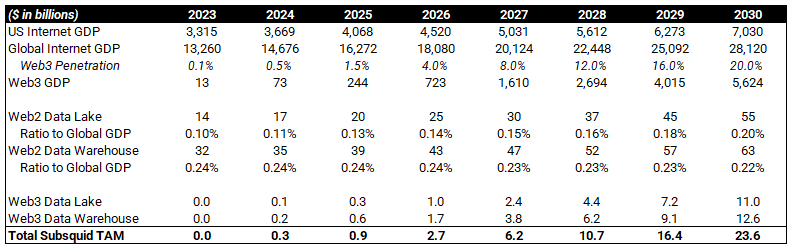
(sources: omnichain observations, future market insights, expert market research)
If we assume Subsquid has 20% market share in 2030 and apply a 10x revenue multiple (reasonable for high growth assets, more below), SQD would be worth $47b, 240x today’s FDV!
Why 20% market share? Looking at the competitive dynamics for Web2 data management providers, the market leader has consistently held 40%+ share over time. Given the more fragmented nature of Web3, we believe 20% is a fair assumption for Subsquid’s upside scenario.
Why 10x revenue? It’s the 10-year average for public cloud computing companies (which reached a high of 22x in 2020!).
Sensitivity tables for Subsquid’s 2030 FDV ($ in billions) and return multiples below:

Investment Thesis
Highly asymmetric risk/reward investment opportunity; Subsquid’s current FDV offers 18x upside to achieve valuation parity with The Graph (GRT), which we believe has objectively inferior technology and network economics, and 240x+ upside longer-term.
Unique and differentiated asset in a highly valuable part of the Web3 technology stack (data lake & warehouse), which will become more important as application complexity continues to accelerate, decentralized AI proliferates, and general industry adoption expands, resulting in exponentially more on-chain data.
Neglected and severely mispriced because of its ineffective brand marketing, lackluster token launch event, and esoteric technical differentiation.
Despite the lack of attention from the market, Subsquid has a networking architecture superior to large incumbents, impressive early customer traction, and an exciting roadmap to offer full data warehouse capabilities, as well as coprocessing and RAG functionality.
Multiple near-term catalysts include its June mainnet launch, imminent website refresh & rebranding efforts, and new focus on marketing & strategic partner initiatives.
Technical Design
Subsquid is designed to provide infinite horizontal scalability, permissionless data access, trust-minimized queries, and low maintenance costs. Its architecture ensures:
Raw data is uploaded into permanent storage by data providers.
Data is compressed and distributed among network nodes.
Node operators bond a security deposit, which can be slashed for byzantine behavior.
Each node efficiently queries local data with DuckDB.
Queries can be verified by submitting a signed response to an on-chain smart contract.
Network Architecture

Data Providers: Data providers ensure the quality and timely provision of data. During the bootstrapping phase, Subsquid Labs GmbH serves as the sole data provider, acting as a proxy for chains from which the data is ingested block-by-block. The ingested data is validated by comparing hashes, then split into small, compressed chunks and saved into persistent storage. These chunks are randomly distributed among workers.

Workers: Contribute storage and compute resources to the network. They serve the data in a peer-to-peer manner for consumption and receive SQD tokens as compensation. Each worker must register on-chain by bonding 100,000 SQD tokens, which can be slashed if they violate protocol rules. SQD holders can also delegate tokens to a specific worker, signaling reliability and earning a portion of the rewards.
Scheduler: Distributes data chunks submitted by data providers among workers. It monitors updates to data sets and worker sets, sending requests to workers to download new chunks or redistribute existing ones based on capacity and redundancy targets. Upon receiving an update request, a worker downloads the missing data chunks from persistent storage.
Logs Collector: Collects liveness pings and query execution logs from workers, batches them, and saves them into public persistent storage. The logs are signed by the workers' P2P identities and pinned to IPFS. This data is stored for at least six months and is used by other network participants.
Rewards Manager: Accesses logs, calculates rewards, and submits a claimable commitment on-chain for each epoch. Workers then claim their rewards individually, which may expire after an extended period.
Data Consumers: Query the network by operating a gateway or using an externally provided service (public or private). Each gateway is bound to an on-chain address. The number of requests a gateway can submit is capped by the amount of locked SQD tokens, effectively yielding virtual "compute units" (CU) based on the lock period. All queries cost 1 CU until complex SQL queries are implemented.

Query Validation
Subsquid Network provides economic guarantees for the validity of queried data, with the possibility of on-chain validation. All query responses are signed by the worker who executed the query, acting as a commitment to the response. If deemed incorrect, the worker's bond is slashed. Validation logic may be dataset-specific, with options including:
Proof by Authority: A whitelist of on-chain identities decides the validity of responses.
Optimistic On-chain: After a validation request, anyone can submit proof of an incorrect response.
Zero-Knowledge: A zero-knowledge proof verifies the response exactly matches the request. The proof is generated off-chain by a prover and validated on-chain by the smart contract.
Future Product Development
While we strongly believe the Subsquid platform is materially undervalued today based on its initial indexing and query capabilities and traction, its long-term upside will be driven by upcoming product launches, like TEE/ZK coprocessing and RAG functionality, which will be indispensable infrastructure for future next-gen, high-utility Web3 applications.
TEE/ZK Coprocessor
Subsquid is developing a coprocessor solution, combining its powerful multi-chain indexing capabilities with 3rd party TEE and ZK provers (Brevis, Polyhedra, Phala) to trustlessly connect on-chain smart contracts with its network of off-chain data lake resources. Rather than develop a single ZK solution in-house, Subsquid believes offering a variety of verification options is ideal for optimizing performance for specific use cases and workloads.
This opens doors to high-compute and data-driven on-chain applications such as order book DEXs, lending protocols, and perpetuals, even on blockchains with low TPS and strict programming languages.
AI Agent / RAG Functionality
It is conceivable that within the next 10 years most of the Internet traffic will be produced and consumed by AI agents. A contrarian view here is that none of the turn-key AI agent platforms are likely to dominate the market, similar to how website building platforms (e.g. Wordpress) serve only a specific hobby-level niche. At the same time, the largest share of the post-2000 boom was captured by Amazon Web Services on the infrastructure side. The flexibility and the ease-of-use of AWS building blocks unlocked the next wave of Internet applications.
We expect the same dynamic to apply in the AI x Blockchain space. However, this time the key bottleneck is likely going to be the data access. Subsquid’s approach is to provide a high-throughput, minimal viable interface for the data access may become the trigger for the growth flywheel, attracting producers of high-quality data and its consumers.
The way data is accessed from the Subsquid Network (customizable gateways and/or general-purpose SDK) unlocks open-ended RAG applications. One example was already implemented: a LLM-enabled agent translating human language questions into queries to the indexed data, implemented with Squid SDK.
Customer Traction & Strategic Partnerships

Number of users, squids (cloud indexers), and archive queries (network queries), as well as network data traffic, have all been up and to the right since testnet launched late last year.


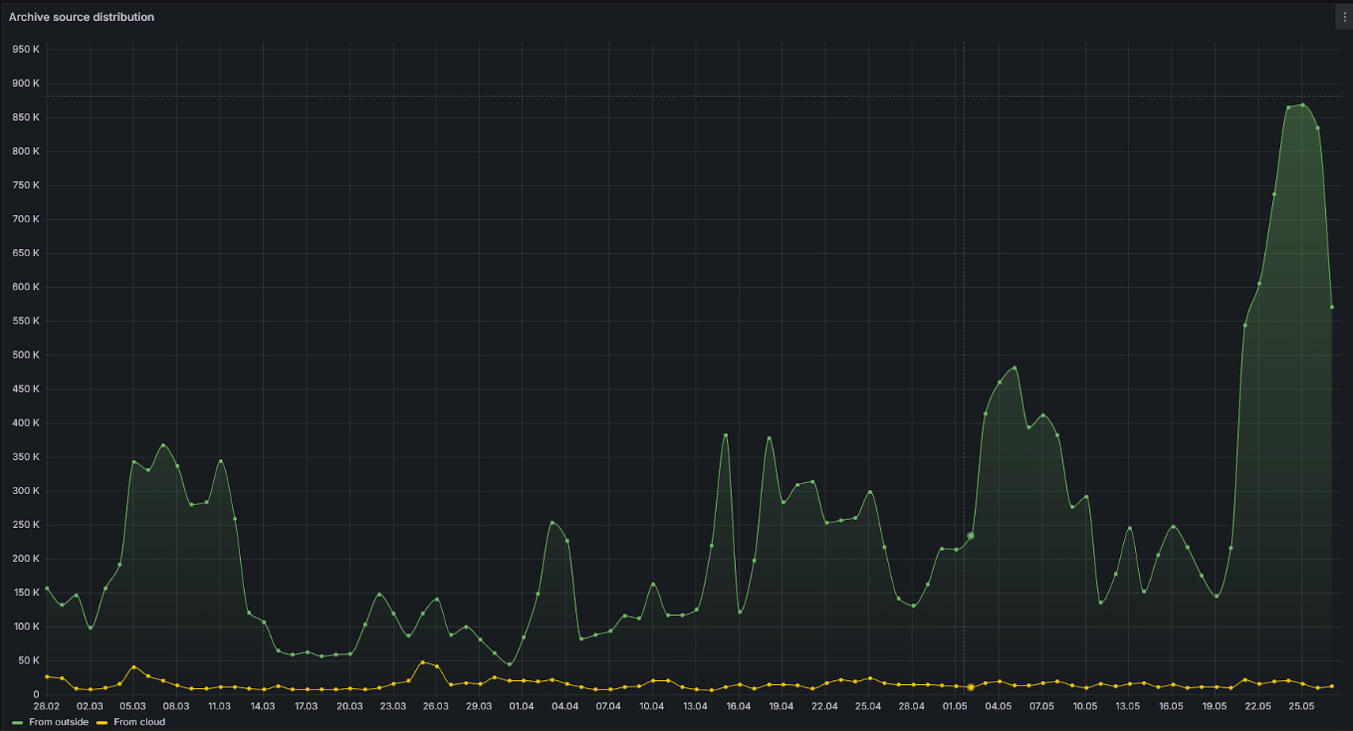

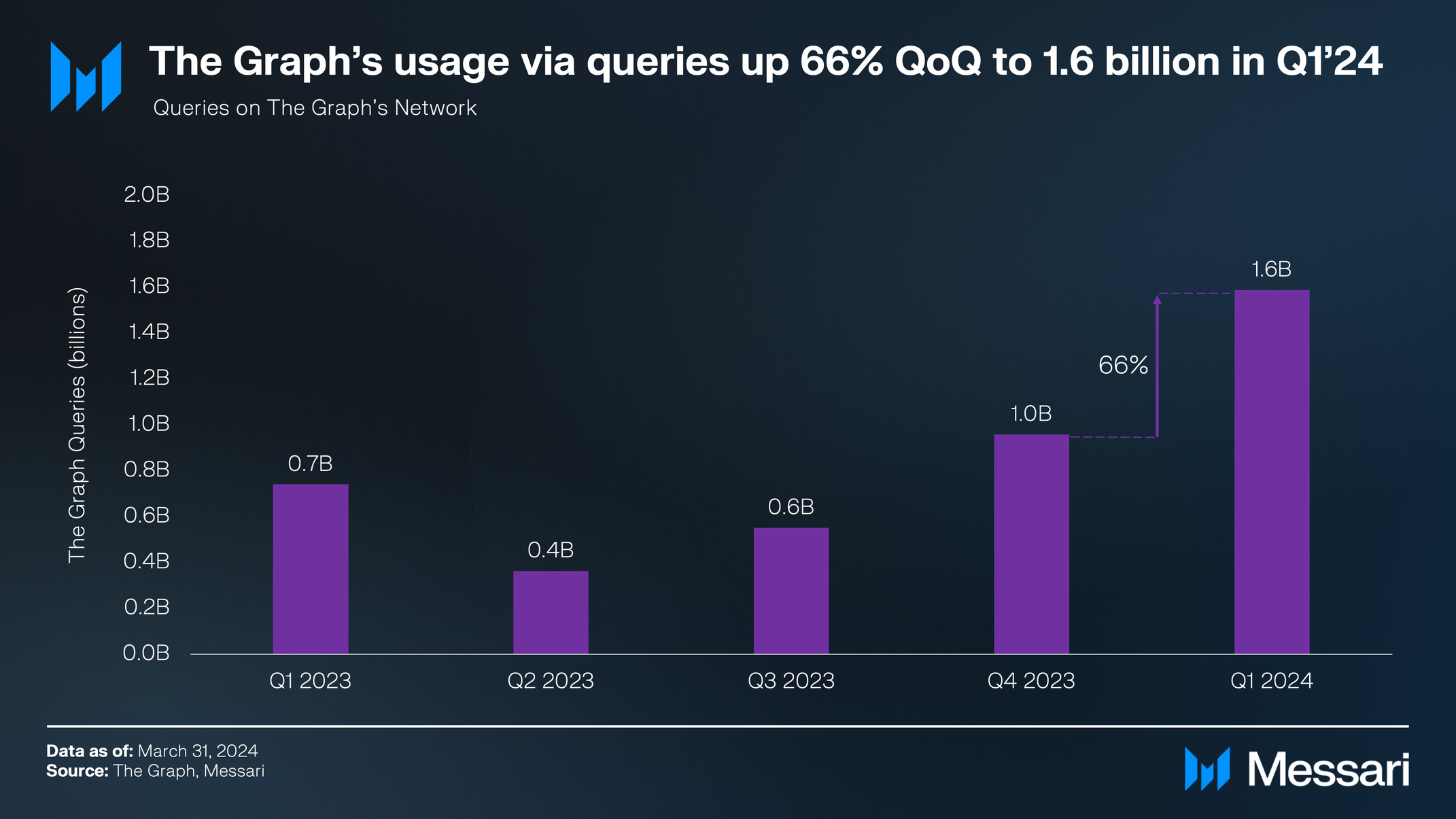
For an apples-to-apples comparison with The Graph, we need to compare end-user queries. Subsquid end-user queries can either be sent from the cloud (which can be tracked) or self-hosted solutions (which cannot be tracked at this time). For Q1 2024, cloud queries totaled 1.2b. Since there were roughly 9x more archive queries from self-hosted implementations (Archive Source Distribution chart above), we can assume self-hosted users also had 9x as many end-user queries. We can therefore estimate ~10b total end-user queries in Q1 for Subsquid, substantially exceeding The Graph, which had 1.6b for the same time period.

Google Cloud Partnership (BigQuery Integration)

Google Cloud’s BigQuery is a powerful enterprise data warehouse solution that allows companies and individuals to store and analyze petabytes of data. Designed for large-scale data analytics, BigQuery supports multi-cloud deployments and offers built-in machine learning capabilities, enabling data scientists to create ML models with simple SQL. BigQuery is also fully integrated with Google's own suite of business intelligence and external tools, empowering users to run their own code inside BigQuery using Jupyter Notebooks or Apache Zeppelin.
Multi-chain projects can leverage Subsquid alongside BigQuery to quickly analyze their usage across different chains and gain insights into fees, operating costs, and trends. Saving custom-curated data to BigQuery lets developers leverage Google's analytics tools to gain insights into how their product is used, beyond the context of one chain or platform.
Roadmap & Upcoming Catalysts
Mainnet: Recently launched on June 3, with enhanced SQD incentives to scale participation planned for July.

Rebrand: Website refresh and new branding strategy expected to launch in the next few weeks.
Cosmos Support: Expands capabilities to the Cosmos ecosystem, broadening the user base.
Permissionless Dataset Submission: Subsquid GmbH currently maintains datasets, with plans for decentralized submission and curation.
Decentralized SQL Database Streaming: Distributes and syncs databases across the data lake, ensuring accuracy and timeliness.
Enterprise Tooling: Implements Kafka for real-time data handling and Snowflake for big data analysis and storage.
Coprocessing & RAG functionality: Currently in PoC, the team will release a more specific product road map in the near future.
Near-Term Re-Rate, Long-Term Growth Story
SQD is one of the most compelling liquid token investment opportunities I’ve ever seen. With multiple upcoming catalysts, we believe the token can re-rate 10-20x near-term, but its longer-term TAM provides an exciting upside potential of 240x+.
A fantastic deep dive. As an early investor into SubSquid I am pleased to learn there are others out there that can see the potential with this project. Much appreciated, I learnt a lot of new things on this piece.